
Prof. Piotr Bała

Code example for PCJ 5: Print Hello World in parallel. Calculations start from a special StartPoint class. That class contains main method (public void main()):
The compilation and execution requires PCJ-5.0.9.jar in the path: javac -cp .:PCJ.jar HelloWorld.java java -cp .:PCJ-5.0.9.jar HelloWorld The expected output is presented below:
Estimate π using integral. Parallelization performed by work distribution (loop parallelization).
The value of πis calculated using rectangles method that approximates following integral:
π = ∫ 4.0 / (1 + x2 ) dx
In our code, the interval is codeided into equal subintervals and we take top middle point of each subinterval to calculate area of the rectangle.
The calculations will start by executing the main method from PcjExamplePiI class. Four tasks will be involved in calculations: on local machine. The listing contains comments that should clarify what program is doing. The user can easily change number of tasks by providing more host names to the deploy method. The PCJ will launch calculations on specified nodes.
import org.pcj.NodesDescription;import org.pcj.PCJ;import org.pcj.StartPoint;import org.pcj.Storage;import org.pcj.PcjFuture;import org.pcj.RegisterStorage;@RegisterStorage(PcjExamplePiI.Shared.class)public class PcjExamplePiI implements StartPoint { private double f(final double x) { return (4.0 / (1.0 + x * x)); } @Storage(PcjExamplePiI.class) enum Shared { sum } double sum; @Override public void main() { PCJ.barrier(); double time = System.nanoTime(); long nAll = 1_280_000_000; double w = 1.0 / (double) nAll; sum = 0.0;// Calculate partial results with the cyclic distribution for (int i = PCJ.myId(); i < nAll; i += PCJ.threadCount()) { sum = sum + f(((double) i + 0.5) * w); } sum = sum * w;// Wait for all tasksk to finish PCJ.barrier();// Gather results PcjFuture cL[] = new PcjFuture[PCJ.threadCount()]; double pi = sum; if (PCJ.myId() == 0) { for (int p = 1; p < PCJ.threadCount(); p++) { cL[p] = PCJ.asyncGet(p, Shared.sum); } for (int p = 1; p < PCJ.threadCount(); p++) { pi = pi + cL[p].get(); } } PCJ.barrier();// Print results time = System.nanoTime() - time; if (PCJ.myId() == 0) { System.out.format(" %.7f %.7f time %.5f \n", pi, time * 1.0E-9, time); } } public static void main(String[] args) throws IOException { String nodesFile = "nodes.txt"; PCJ.executionBuilder (PcjExample.class) .addNodes(new File("nodes.txt")) .start(); }}Reduction operation is widely used to gather values of some variable stored on different threads.
import java.io.IOException;import org.pcj.*;@RegisterStorage(PcjReduction.Shared.class)public class PcjReduction implements StartPoint {@Storage(PcjExample.class)enum Shared { a }public long a;public static void main(String[] args) throws IOException { String nodesFile = "nodes.txt"; PCJ.executionBuilder (PcjExample.class) .addNodes(new File("nodes.txt")) .start();}@Overridepublic void main() throws Throwable { a = PCJ.myId() + 10; // set value of a long sum = 0; if (PCJ.myId() == 0) { sum = PCJ.reduce(Lomg::sum, Shared.a); } PCJ.barrier(); System.out.println(PCJ.myId()+ " "+ sum);}}In the presented example the values are communicated to the thread with the id 0. Than reduction operation such as summation is performed. Than value of the variable a (Shared variable) stored at the thread p is communicated to the thread 0 and added to the local variable sum.
import java.io.IOException;import org.pcj.*;@RegisterStorage(PcjReductionGet.Shared.class)public class PcjReductionGet implements StartPoint {@Storage(PcjReductionGet.class)enum Shared { a }long a;public static void main(String[] args) throws IOException {String nodesFile = "nodes.txt";PCJ.executionBuilder (PcjExample.class).addNodes(new File("nodes.txt")).start();}@Overridepublic void main() throws Throwable {a = PCJ.myId() + 10; // set value of along sum = 0;PCJ.barrier();if (PCJ.myId() == 0) {for (int p = 1; p < PCJ.threadCount(); p++) { sum=sum + (long) PCJ.get(p, Shared.a); } }
PCJ.barrier(); System.out.println(PCJ.myId()+ " " + sum); } }The presented algorithm of the reduction is based on the synchronous communication PCJ.get(). The summation is performed at thread 0 as data is arrived.
The asynchronous version requires additional storage at the thread 0. The al[]variable stores values of a variable communicated in asynchronous way:
import java.io.IOException;import org.pcj.*;@RegisterStorage(PcjReductionGet.Shared.class)public class PcjReductionGet implements StartPoint {@Storage(PcjReductionGet.class)enum Shared { a }long a;public static void main(String[] args) throws IOException {String nodesFile = "nodes.txt";PCJ.executionBuilder (PcjExample.class).addNodes(new File("nodes.txt")).start();}@Overridepublic void main() throws Throwable {PcjFuture aL[] = new PcjFuture[PCJ.threadCount()];PCJ.barrier();long sum;if (PCJ.myId() == 0) { // Asynchronous communicationfor (int p = 0; p < PCJ.threadCount(); p++) { aL[p]=PCJ.asyncGet(p, Shared.a); } }
PCJ.barrier(); // Synchronization sum=0; if (PCJ.myId()==0) { // Sumation of local values for (int p=0; p < PCJ.threadCount();
p++) { sum=sum + (long) aL[p].get(); } } System.out.println(PCJ.myId() + " " + sum); } }Estimate π using Monte Carlo method (parallelization of workload).
The program picks points at random inside the square. It then checks to see if the point is inside the circle (it knows it’s inside the circle if x^2 + y^2 < R^2, where x and y are the coordinates of the point and R is the radius of the circle).
The program keeps track of how many points it’s picked (nAll) and how many of those points fell inside the circle(circleCount).
In the parallel version, the work is divided among threads, i.e. each traed is performing nAll / PCJ.threadsCount() attempts. Each thread counts points inside circle.
Finally, the parrial sums are communicated to the procesor 0.
import java.util.Random;
import org.pcj.NodesDescription;
import org.pcj.PCJ;
import org.pcj.StartPoint;
import org.pcj.Storage;
import org.pcj.PcjFuture;
import org.pcj.RegisterStorage;
@RegisterStorage(PcjExamplePiMC.Shared.class)
public class PcjExamplePiMC implements StartPoint {
@Storage(PcjExamplePiMC.class)
enum Shared { c }
long c;
@Override
public void main() {
PCJ.barrier();
Random r = new Random();
long nAll = 1000000;
long n = nAll / PCJ.threadCount();
double Rsq = 1.0;
long circleCount;
//Calculate
circleCount = 0;
double time = System.nanoTime();
for (long i = 0; i < n; i++) {
double x = 2.0 * r.nextDouble() - 1.0;
double y = 2.0 * r.nextDouble() - 1.0;
if ((x * x + y * y) < Rsq) {
circleCount++;
}
}
c = circleCount;
PCJ.barrier();
// Communicate results
PcjFuture cL[] = new PcjFuture[PCJ.threadCount()];
long c0 = c;
if (PCJ.myId() == 0) {
for (int p = 1; p < PCJ.threadCount(); p++) {
cL[p] = PCJ.asyncGet(p, Shared.c);
}
for (int p = 1; p < PCJ.threadCount(); p++) {
c0 = c0 + (long) cL[p].get();
}
}
PCJ.barrier();
double pi = 4.0 * (double) c0 / (double) nAll;
time = System.nanoTime() - time;
// Print results
if (PCJ.myId() == 0) {
System.out.println(pi + " " + time * 1.0E-9);
}
}
public static void main(String[] args) {
String nodesFile = "nodes.txt";
PCJ.executionBuilder (PcjExample.class)
.addNodes(new File("nodes.txt"))
.start();
}
}
}
The code scales linearly with the numbers of processors.
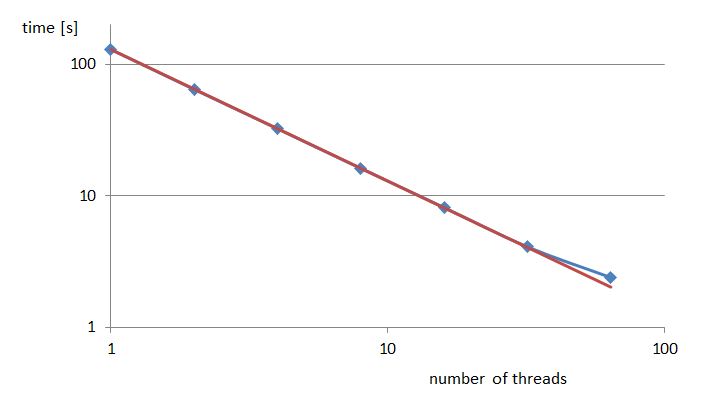
The performance of the code to approximate π using Monte Carlo method.